
Turinys:
ToggleTrumpai tariant
- „DeepSeek V4“ gali sumažėti per kelias savaites, taikydamas elito lygio kodavimo našumą.
- Viešai neatskleista informacija teigia, kad tai galėtų įveikti Claude'ą ir ChatGPT atliekant ilgo konteksto kodo užduotis.
- Kūrėjai jau yra sujaudinti prieš galimą sutrikimą.
Pranešama, kad „DeepSeek“ planuoja atsisakyti savo V4 modelio maždaug vasario viduryje, o jei vidiniai testai rodo kokių nors požymių, Silicio slėnio dirbtinio intelekto milžinai turėtų sunerimti.
Hangdžou pagrįstas dirbtinio intelekto startuolis gali siekti, kad jis bus išleistas maždaug vasario 17 d., savaime suprantama, pagal Naujuosius Mėnulio metus, su modeliu, specialiai sukurtu kodavimo užduotims atlikti. Informacija. Žmonės, tiesiogiai žinantys apie projektą, teigia, kad V4 viršija Anthropic Claude ir OpenAI GPT serijas pagal vidinius etalonus, ypač kai tvarko itin ilgus kodo raginimus.
Žinoma, joks etalonas ar informacija apie modelį nebuvo viešai pasidalinta, todėl tiesiogiai patikrinti tokių teiginių neįmanoma. „DeepSeek“ gandų taip pat nepatvirtino.
Vis dėlto kūrėjų bendruomenė nelaukia oficialaus žodžio. „Reddit“ r/DeepSeek ir r/LocalLLaMA jau įkaista, vartotojai kaupia API kreditus, o X entuziastai greitai pasidalijo savo prognozėmis, kad V4 gali sustiprinti „DeepSeek“ kaip niekšiško varžovo, atsisakančio žaisti pagal Silicio slėnio milijardų dolerių taisykles, poziciją.
Anthropic užblokavo Claude prenumeratorius trečiųjų šalių programose, pvz., OpenCode, ir, kaip pranešama, nutraukė prieigą prie xAI ir OpenAI.
Claude ir Claude Code yra puikūs, bet dar ne 10 kartų geresni. Tai tik paskatins kitas laboratorijas greičiau pereiti prie savo kodavimo modelių / agentų.
Sklando gandai, kad „DeepSeek V4“ nustos…
– Yuchen Jin (@Yuchenj_UW) 2026 m. sausio 9 d
Tai nebūtų pirmasis „DeepSeek“ sutrikimas. Kai 2025 m. sausio mėn. bendrovė išleido savo R1 samprotavimo modelį, pasaulinėse rinkose jis išpardavo 1 trilijoną USD.
Priežastis? DeepSeek R1 atitiko OpenAI o1 modelį matematikos ir samprotavimo etalonų srityje, nors pranešama, kad jo sukūrimas kainavo tik 6 mln. USD – maždaug 68 kartus pigiau, nei išleido konkurentai. Vėliau jo V3 modelis pasiekė 90,2% pagal MATH-500 etaloną, pralenkdamas Claude'o 78,3%, o neseniai atnaujintas „V3.2 Speciale“ dar labiau pagerino jo veikimą.
V4 kodavimo dėmesys būtų strateginis posūkis. Nors R1 pabrėžė gryną samprotavimą – logiką, matematiką, formalius įrodymus, V4 yra hibridinis modelis (samprotavimo ir nemotyvavimo užduotys), skirtas įmonių kūrėjų rinkai, kurioje didelio tikslumo kodo generavimas tiesiogiai reiškia pajamas.
Kad įgytų dominavimą, V4 turėtų įveikti Claude Opus 4.5, kuriam šiuo metu priklauso SWE-bench Verified rekordas – 80,9%. Tačiau jei ankstesni „DeepSeek“ paleidimai yra bet koks vadovas, tai gali būti neįmanoma pasiekti net ir esant visais suvaržymais, su kuriais susidurtų Kinijos AI laboratorija.
Nelabai slaptas padažas
Darant prielaidą, kad gandai yra teisingi, kaip ši maža laboratorija gali pasiekti tokį žygdarbį?
Slaptas bendrovės ginklas gali būti pateiktas sausio 1 d. tyrimo dokumente: „Manifold-Constrained Hyper-Connections“ arba mHC. Naujasis mokymo metodas, kurio bendraautoris yra įkūrėjas Liangas Wenfengas, sprendžia esminę didelių kalbų modelių mastelio keitimo problemą – kaip išplėsti modelio pajėgumą, kad jis netaptų nestabilus ar nesprogtų treniruočių metu.
Tradicinės AI architektūros perkelia visą informaciją vienu siauru keliu. mHC išplečia šį kelią į kelis srautus, kurie gali keistis informacija nesukeldami treniruočių žlugimo.
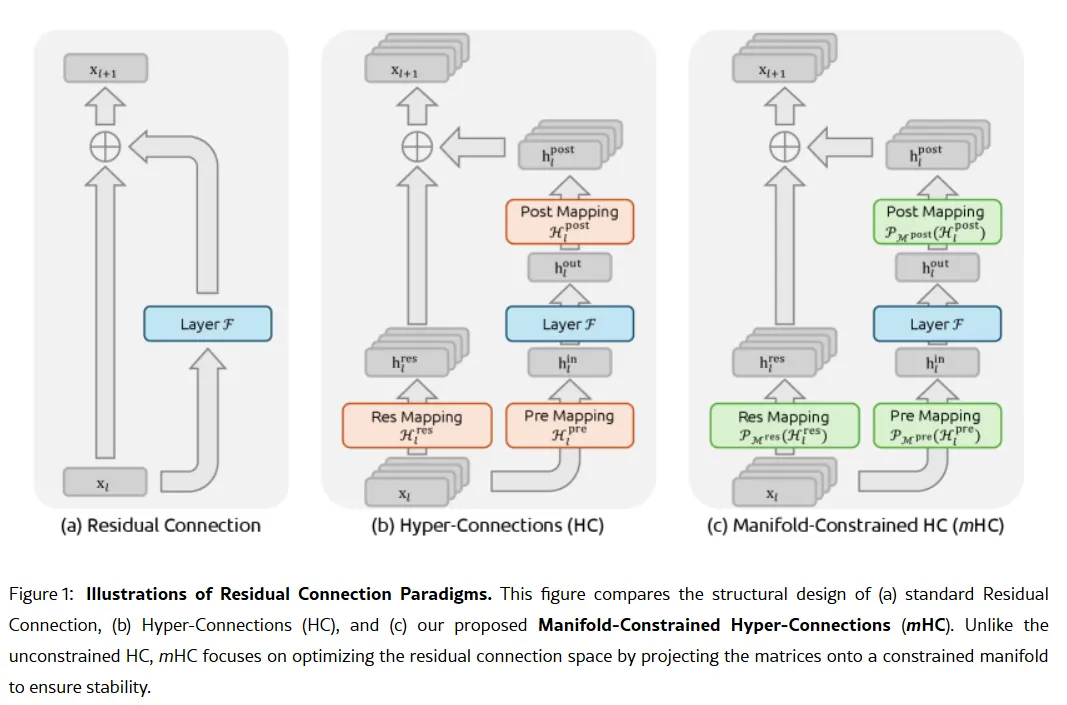
Wei Sun, pagrindinis „Counterpoint Research“ dirbtinio intelekto analitikas, komentuodamas mHC pavadino „stulbinamu proveržiu“. Business Insider. Pasak jos, ši technika rodo, kad „DeepSeek“ gali „apeiti skaičiavimo kliūtis ir atverti žvalgybos šuolius“, net ir turėdamas ribotą prieigą prie pažangių lustų dėl JAV eksporto apribojimų.
Lianas Jye Su, vyriausiasis „Omdia“ analitikas, pažymėjo, kad „DeepSeek“ noras skelbti savo metodus rodo „naujai atrastą pasitikėjimą Kinijos AI pramone“. Bendrovės atvirojo kodo metodas pavertė ją numylėtiniu tarp kūrėjų, kurie mano, kad ji įkūnija tai, kas anksčiau buvo OpenAI, prieš tai, kai ji buvo nukreipta į uždarus modelius ir milijardų dolerių lėšų rinkimo ratus.
Ne visi tuo įsitikinę. Kai kurie „Reddit“ kūrėjai skundžiasi, kad „DeepSeek“ samprotavimo modeliai skaičiuoja paprastas užduotis, o kritikai teigia, kad bendrovės etalonai neatspindi tikrojo pasaulio netvarkos. Vienas „Medium“ įrašas pavadinimu „DeepSeek Sucks – And I'm Done Pretending It Doesn't“ išplito 2025 m. balandžio mėn., kaltindamas modelius gaminant „nesąmones su klaidomis“ ir „haliucinuotas bibliotekas“.
„DeepSeek“ taip pat gabena bagažą. Susirūpinimas dėl privatumo kėlė kompaniją, kai kurios vyriausybės uždraudė „DeepSeek“ vietinę programą. Bendrovės ryšiai su Kinija ir klausimai apie cenzūrą jos modeliuose prideda geopolitinės trinties techninėms diskusijoms.
Vis dėlto pagreitis nenuginčijamas. „Deepseek“ buvo plačiai pritaikytas Azijoje ir, jei V4 įvykdys savo kodavimo pažadus, Vakaruose gali būti pritaikyta įmonėms.
Taip pat yra laikas. Pagal Reuters„DeepSeek“ iš pradžių planavo išleisti savo R2 modelį 2025 m. gegužę, tačiau pratęsė kilimo ir tūpimo taką, kai įkūrėjas Liangas buvo nepatenkintas jo veikimu. Dabar, kai pranešama, kad V4 taikosi vasario mėn., o R2 – galbūt rugpjūtį, bendrovė juda tokiu tempu, kuris rodo skubumą arba pasitikėjimą. Galbūt abu.
Apskritai protingas Naujienlaiškis
Savaitinė AI kelionė, pasakojama Geno, generatyvaus AI modelio.


